Text Mining with R¶
Setup¶
Install and load packages¶
We will be using several external libraries to do our text analysis.
install.packages("readtext")
install.packages("quanteda")
install.packages("quanteda.textmodels")
install.packages("quanteda.textstats")
install.packages("quanteda.textplots")
install.packages("tidyverse")
library(readtext)
library(quanteda)
library(quanteda.textmodels)
library(quanteda.textstats)
library(quanteda.textplots)
library(tidyverse)
Import data¶
We are going to analyze the State of the Union Addresses from 1934 to 2020. First, set your working directory to the location of your files.
setwd('~/Documents/Workshops/TM2023/') # replace with the appropriate directory
sotu<- readtext ("texts")
sotu
readtext object consisting of 96 documents and 0 docvars.
# Description: df [96 × 2]
doc_id text
<chr> <chr>
1 barack-obama-2009.txt "\"Madam Spea\"..."
2 barack-obama-2010.txt "\"Madam Spea\"..."
3 barack-obama-2011.txt "\"Mr. Speake\"..."
4 barack-obama-2012.txt "\"Mr. Speake\"..."
5 barack-obama-2013.txt "\"Please, ev\"..."
6 barack-obama-2014.txt "\"The Presid\"..."
# … with 90 more rows
Create a corpus¶
A corpus is a structure for text analysis that retains the position of the words.
sotu_corp <- corpus(sotu)
sotu_corp
Corpus consisting of 96 documents.
barack-obama-2009.txt :
"Madam Speaker, Mr. Vice President, Members of Congress, the ..."
barack-obama-2010.txt :
"Madam Speaker, Vice President Biden, Members of Congress, di..."
barack-obama-2011.txt :
"Mr. Speaker, Mr. Vice President, Members of Congress, distin..."
barack-obama-2012.txt :
"Mr. Speaker, Mr. Vice President, Members of Congress, distin..."
barack-obama-2013.txt :
"Please, everybody, have a seat. Mr. Speaker, Mr. Vice Presid..."
barack-obama-2014.txt :
"The President. Mr. Speaker, Mr. Vice President, Members of C..."
[ reached max_ndoc ... 90 more documents ]
Let’s take a look at a few statistics describing the corpus.
ndoc(sotu_corp) # document count
[1] 96
docnames(sotu_corp) # unique document identifiers
[1] "barack-obama-2009.txt" "barack-obama-2010.txt"
[3] "barack-obama-2011.txt" "barack-obama-2012.txt"
[5] "barack-obama-2013.txt" "barack-obama-2014.txt"
[7] "barack-obama-2015.txt" "barack-obama-2016.txt"
[9] "donald-trump-2017.txt" "donald-trump-2018.txt"
[11] "donald-trump-2019.txt" "donald-trump-2020.txt"
[13] "dwight-d-eisenhower-1953.txt" "dwight-d-eisenhower-1954.txt"
[15] "dwight-d-eisenhower-1955.txt" "dwight-d-eisenhower-1956a.txt"
[17] "dwight-d-eisenhower-1956b.txt" "dwight-d-eisenhower-1957.txt"
[19] "dwight-d-eisenhower-1958.txt" "dwight-d-eisenhower-1959.txt"
[21] "dwight-d-eisenhower-1960.txt" "dwight-d-eisenhower-1961.txt"
[23] "franklin-d-roosevelt-1934.txt" "franklin-d-roosevelt-1935.txt"
[25] "franklin-d-roosevelt-1936.txt" "franklin-d-roosevelt-1937.txt"
[27] "franklin-d-roosevelt-1938.txt" "franklin-d-roosevelt-1939.txt"
[29] "franklin-d-roosevelt-1940.txt" "franklin-d-roosevelt-1941.txt"
[31] "franklin-d-roosevelt-1942.txt" "franklin-d-roosevelt-1943.txt"
[33] "franklin-d-roosevelt-1944.txt" "franklin-d-roosevelt-1945a.txt"
[35] "franklin-d-roosevelt-1945b.txt" "george-bush-1989.txt"
[37] "george-bush-1990.txt" "george-bush-1991.txt"
[39] "george-bush-1992.txt" "george-w-bush-2001.txt"
[41] "george-w-bush-2002.txt" "george-w-bush-2003.txt"
[43] "george-w-bush-2004.txt" "george-w-bush-2005.txt"
[45] "george-w-bush-2006.txt" "george-w-bush-2007.txt"
[47] "george-w-bush-2008.txt" "gerald-r-ford-1975.txt"
[49] "gerald-r-ford-1976.txt" "gerald-r-ford-1977.txt"
[51] "harry-s-truman-1946.txt" "harry-s-truman-1947.txt"
[53] "harry-s-truman-1948.txt" "harry-s-truman-1949.txt"
[55] "harry-s-truman-1950.txt" "harry-s-truman-1951.txt"
[57] "harry-s-truman-1952.txt" "harry-s-truman-1953.txt"
[59] "jimmy-carter-1978a.txt" "jimmy-carter-1978b.txt"
[61] "jimmy-carter-1979a.txt" "jimmy-carter-1979b.txt"
[63] "jimmy-carter-1980a.txt" "jimmy-carter-1980b.txt"
[65] "jimmy-carter-1981.txt" "john-f-kennedy-1961.txt"
[67] "john-f-kennedy-1962.txt" "john-f-kennedy-1963.txt"
[69] "lyndon-b-johnson-1964.txt" "lyndon-b-johnson-1965.txt"
[71] "lyndon-b-johnson-1966.txt" "lyndon-b-johnson-1967.txt"
[73] "lyndon-b-johnson-1968.txt" "lyndon-b-johnson-1969.txt"
[75] "richard-m-nixon-1970.txt" "richard-m-nixon-1971.txt"
[77] "richard-m-nixon-1972a.txt" "richard-m-nixon-1972b.txt"
[79] "richard-m-nixon-1974a.txt" "richard-m-nixon-1974b.txt"
[81] "ronald-reagan-1981.txt" "ronald-reagan-1982.txt"
[83] "ronald-reagan-1983.txt" "ronald-reagan-1984.txt"
[85] "ronald-reagan-1985.txt" "ronald-reagan-1986.txt"
[87] "ronald-reagan-1987.txt" "ronald-reagan-1988.txt"
[89] "william-j-clinton-1993.txt" "william-j-clinton-1994.txt"
[91] "william-j-clinton-1995.txt" "william-j-clinton-1996.txt"
[93] "william-j-clinton-1997.txt" "william-j-clinton-1998.txt"
[95] "william-j-clinton-1999.txt" "william-j-clinton-2000.txt"
ntoken(sotu_corp) # tokens in each document
barack-obama-2009.txt barack-obama-2010.txt
6743 8151
barack-obama-2011.txt barack-obama-2012.txt
7741 7836
barack-obama-2013.txt barack-obama-2014.txt
7580 7908
barack-obama-2015.txt barack-obama-2016.txt
7622 6837
donald-trump-2017.txt donald-trump-2018.txt
5702 5865
donald-trump-2019.txt donald-trump-2020.txt
5895 7145
dwight-d-eisenhower-1953.txt dwight-d-eisenhower-1954.txt
7704 6596
dwight-d-eisenhower-1955.txt dwight-d-eisenhower-1956a.txt
8039 1192
dwight-d-eisenhower-1956b.txt dwight-d-eisenhower-1957.txt
9070 4562
dwight-d-eisenhower-1958.txt dwight-d-eisenhower-1959.txt
5487 5482
dwight-d-eisenhower-1960.txt dwight-d-eisenhower-1961.txt
6241 6865
franklin-d-roosevelt-1934.txt franklin-d-roosevelt-1935.txt
2422 3857
franklin-d-roosevelt-1936.txt franklin-d-roosevelt-1937.txt
4251 2977
franklin-d-roosevelt-1938.txt franklin-d-roosevelt-1939.txt
5117 4165
franklin-d-roosevelt-1940.txt franklin-d-roosevelt-1941.txt
3511 3658
franklin-d-roosevelt-1942.txt franklin-d-roosevelt-1943.txt
3912 5071
franklin-d-roosevelt-1944.txt franklin-d-roosevelt-1945a.txt
4219 3441
franklin-d-roosevelt-1945b.txt george-bush-1989.txt
8895 5474
george-bush-1990.txt george-bush-1991.txt
4312 4481
george-bush-1992.txt george-w-bush-2001.txt
5771 4927
george-w-bush-2002.txt george-w-bush-2003.txt
4323 6028
george-w-bush-2004.txt george-w-bush-2005.txt
5790 5628
george-w-bush-2006.txt george-w-bush-2007.txt
5908 6161
george-w-bush-2008.txt gerald-r-ford-1975.txt
6345 4621
gerald-r-ford-1976.txt gerald-r-ford-1977.txt
5505 5246
harry-s-truman-1946.txt harry-s-truman-1947.txt
30890 6619
harry-s-truman-1948.txt harry-s-truman-1949.txt
5575 3764
harry-s-truman-1950.txt harry-s-truman-1951.txt
5588 4415
harry-s-truman-1952.txt harry-s-truman-1953.txt
5919 10869
jimmy-carter-1978a.txt jimmy-carter-1978b.txt
5051 13225
jimmy-carter-1979a.txt jimmy-carter-1979b.txt
3639 23426
jimmy-carter-1980a.txt jimmy-carter-1980b.txt
3801 36401
jimmy-carter-1981.txt john-f-kennedy-1961.txt
36774 5835
john-f-kennedy-1962.txt john-f-kennedy-1963.txt
7419 6040
lyndon-b-johnson-1964.txt lyndon-b-johnson-1965.txt
3603 4895
lyndon-b-johnson-1966.txt lyndon-b-johnson-1967.txt
6174 8024
lyndon-b-johnson-1968.txt lyndon-b-johnson-1969.txt
5524 4605
richard-m-nixon-1970.txt richard-m-nixon-1971.txt
4934 4971
richard-m-nixon-1972a.txt richard-m-nixon-1972b.txt
4424 18979
richard-m-nixon-1974a.txt richard-m-nixon-1974b.txt
5690 24507
ronald-reagan-1981.txt ronald-reagan-1982.txt
4920 5765
ronald-reagan-1983.txt ronald-reagan-1984.txt
6156 5563
ronald-reagan-1985.txt ronald-reagan-1986.txt
4725 3904
ronald-reagan-1987.txt ronald-reagan-1988.txt
4286 5402
william-j-clinton-1993.txt william-j-clinton-1994.txt
7698 8285
william-j-clinton-1995.txt william-j-clinton-1996.txt
10203 7038
william-j-clinton-1997.txt william-j-clinton-1998.txt
7548 8202
william-j-clinton-1999.txt william-j-clinton-2000.txt
8436 10222
ntype(sotu_corp) # types (unique tokens) in each document
barack-obama-2009.txt barack-obama-2010.txt
1587 1844
barack-obama-2011.txt barack-obama-2012.txt
1832 1889
barack-obama-2013.txt barack-obama-2014.txt
1865 1971
barack-obama-2015.txt barack-obama-2016.txt
1828 1723
donald-trump-2017.txt donald-trump-2018.txt
1574 1716
donald-trump-2019.txt donald-trump-2020.txt
1742 1961
dwight-d-eisenhower-1953.txt dwight-d-eisenhower-1954.txt
1930 1788
dwight-d-eisenhower-1955.txt dwight-d-eisenhower-1956a.txt
1948 453
dwight-d-eisenhower-1956b.txt dwight-d-eisenhower-1957.txt
2167 1374
dwight-d-eisenhower-1958.txt dwight-d-eisenhower-1959.txt
1533 1624
dwight-d-eisenhower-1960.txt dwight-d-eisenhower-1961.txt
1818 2042
franklin-d-roosevelt-1934.txt franklin-d-roosevelt-1935.txt
858 1145
franklin-d-roosevelt-1936.txt franklin-d-roosevelt-1937.txt
1215 987
franklin-d-roosevelt-1938.txt franklin-d-roosevelt-1939.txt
1369 1225
franklin-d-roosevelt-1940.txt franklin-d-roosevelt-1941.txt
1050 1100
franklin-d-roosevelt-1942.txt franklin-d-roosevelt-1943.txt
1116 1388
franklin-d-roosevelt-1944.txt franklin-d-roosevelt-1945a.txt
1234 1035
franklin-d-roosevelt-1945b.txt george-bush-1989.txt
2084 1505
george-bush-1990.txt george-bush-1991.txt
1206 1302
george-bush-1992.txt george-w-bush-2001.txt
1497 1298
george-w-bush-2002.txt george-w-bush-2003.txt
1333 1661
george-w-bush-2004.txt george-w-bush-2005.txt
1579 1576
george-w-bush-2006.txt george-w-bush-2007.txt
1642 1689
george-w-bush-2008.txt gerald-r-ford-1975.txt
1694 1327
gerald-r-ford-1976.txt gerald-r-ford-1977.txt
1487 1478
harry-s-truman-1946.txt harry-s-truman-1947.txt
3956 1652
harry-s-truman-1948.txt harry-s-truman-1949.txt
1379 1122
harry-s-truman-1950.txt harry-s-truman-1951.txt
1336 1070
harry-s-truman-1952.txt harry-s-truman-1953.txt
1381 2190
jimmy-carter-1978a.txt jimmy-carter-1978b.txt
1340 2728
jimmy-carter-1979a.txt jimmy-carter-1979b.txt
1071 3710
jimmy-carter-1980a.txt jimmy-carter-1980b.txt
1070 4858
jimmy-carter-1981.txt john-f-kennedy-1961.txt
5188 1714
john-f-kennedy-1962.txt john-f-kennedy-1963.txt
2047 1677
lyndon-b-johnson-1964.txt lyndon-b-johnson-1965.txt
1103 1344
lyndon-b-johnson-1966.txt lyndon-b-johnson-1967.txt
1500 1842
lyndon-b-johnson-1968.txt lyndon-b-johnson-1969.txt
1440 1208
richard-m-nixon-1970.txt richard-m-nixon-1971.txt
1270 1149
richard-m-nixon-1972a.txt richard-m-nixon-1972b.txt
1164 3286
richard-m-nixon-1974a.txt richard-m-nixon-1974b.txt
1267 3815
ronald-reagan-1981.txt ronald-reagan-1982.txt
1382 1608
ronald-reagan-1983.txt ronald-reagan-1984.txt
1681 1612
ronald-reagan-1985.txt ronald-reagan-1986.txt
1478 1260
ronald-reagan-1987.txt ronald-reagan-1988.txt
1343 1506
william-j-clinton-1993.txt william-j-clinton-1994.txt
1564 1767
william-j-clinton-1995.txt william-j-clinton-1996.txt
1939 1584
william-j-clinton-1997.txt william-j-clinton-1998.txt
1719 1964
william-j-clinton-1999.txt william-j-clinton-2000.txt
1932 2113
nsentence(sotu_corp) # sentences in each document
barack-obama-2009.txt barack-obama-2010.txt
286 419
barack-obama-2011.txt barack-obama-2012.txt
395 415
barack-obama-2013.txt barack-obama-2014.txt
361 376
barack-obama-2015.txt barack-obama-2016.txt
376 360
donald-trump-2017.txt donald-trump-2018.txt
290 316
donald-trump-2019.txt donald-trump-2020.txt
293 400
dwight-d-eisenhower-1953.txt dwight-d-eisenhower-1954.txt
350 287
dwight-d-eisenhower-1955.txt dwight-d-eisenhower-1956a.txt
332 52
dwight-d-eisenhower-1956b.txt dwight-d-eisenhower-1957.txt
378 189
dwight-d-eisenhower-1958.txt dwight-d-eisenhower-1959.txt
248 260
dwight-d-eisenhower-1960.txt dwight-d-eisenhower-1961.txt
255 263
franklin-d-roosevelt-1934.txt franklin-d-roosevelt-1935.txt
72 139
franklin-d-roosevelt-1936.txt franklin-d-roosevelt-1937.txt
165 104
franklin-d-roosevelt-1938.txt franklin-d-roosevelt-1939.txt
173 168
franklin-d-roosevelt-1940.txt franklin-d-roosevelt-1941.txt
121 148
franklin-d-roosevelt-1942.txt franklin-d-roosevelt-1943.txt
170 200
franklin-d-roosevelt-1944.txt franklin-d-roosevelt-1945a.txt
167 136
franklin-d-roosevelt-1945b.txt george-bush-1989.txt
338 290
george-bush-1990.txt george-bush-1991.txt
198 226
george-bush-1992.txt george-w-bush-2001.txt
320 276
george-w-bush-2002.txt george-w-bush-2003.txt
215 299
george-w-bush-2004.txt george-w-bush-2005.txt
275 239
george-w-bush-2006.txt george-w-bush-2007.txt
276 285
george-w-bush-2008.txt gerald-r-ford-1975.txt
310 216
gerald-r-ford-1976.txt gerald-r-ford-1977.txt
271 213
harry-s-truman-1946.txt harry-s-truman-1947.txt
1266 291
harry-s-truman-1948.txt harry-s-truman-1949.txt
274 185
harry-s-truman-1950.txt harry-s-truman-1951.txt
232 229
harry-s-truman-1952.txt harry-s-truman-1953.txt
292 431
jimmy-carter-1978a.txt jimmy-carter-1978b.txt
248 507
jimmy-carter-1979a.txt jimmy-carter-1979b.txt
160 861
jimmy-carter-1980a.txt jimmy-carter-1980b.txt
166 1339
jimmy-carter-1981.txt john-f-kennedy-1961.txt
1332 200
john-f-kennedy-1962.txt john-f-kennedy-1963.txt
269 212
lyndon-b-johnson-1964.txt lyndon-b-johnson-1965.txt
139 257
lyndon-b-johnson-1966.txt lyndon-b-johnson-1967.txt
265 353
lyndon-b-johnson-1968.txt lyndon-b-johnson-1969.txt
208 194
richard-m-nixon-1970.txt richard-m-nixon-1971.txt
192 178
richard-m-nixon-1972a.txt richard-m-nixon-1972b.txt
158 728
richard-m-nixon-1974a.txt richard-m-nixon-1974b.txt
204 786
ronald-reagan-1981.txt ronald-reagan-1982.txt
220 248
ronald-reagan-1983.txt ronald-reagan-1984.txt
259 292
ronald-reagan-1985.txt ronald-reagan-1986.txt
222 175
ronald-reagan-1987.txt ronald-reagan-1988.txt
204 223
william-j-clinton-1993.txt william-j-clinton-1994.txt
292 396
william-j-clinton-1995.txt william-j-clinton-1996.txt
460 356
william-j-clinton-1997.txt william-j-clinton-1998.txt
346 366
william-j-clinton-1999.txt william-j-clinton-2000.txt
392 493
summary(sotu_corp)# to get types, tokens, sentences
Corpus consisting of 96 documents, showing 96 documents:
Text Types Tokens Sentences
barack-obama-2009.txt 1587 6743 286
barack-obama-2010.txt 1844 8151 419
barack-obama-2011.txt 1832 7741 395
barack-obama-2012.txt 1889 7836 415
barack-obama-2013.txt 1865 7580 361
barack-obama-2014.txt 1971 7908 376
barack-obama-2015.txt 1828 7622 376
barack-obama-2016.txt 1723 6837 360
donald-trump-2017.txt 1574 5702 290
donald-trump-2018.txt 1716 5865 316
donald-trump-2019.txt 1742 5895 293
donald-trump-2020.txt 1961 7145 400
dwight-d-eisenhower-1953.txt 1930 7704 350
dwight-d-eisenhower-1954.txt 1788 6596 287
dwight-d-eisenhower-1955.txt 1948 8039 332
dwight-d-eisenhower-1956a.txt 453 1192 52
dwight-d-eisenhower-1956b.txt 2167 9070 378
dwight-d-eisenhower-1957.txt 1374 4562 189
dwight-d-eisenhower-1958.txt 1533 5487 248
dwight-d-eisenhower-1959.txt 1624 5482 260
dwight-d-eisenhower-1960.txt 1818 6241 255
dwight-d-eisenhower-1961.txt 2042 6865 263
franklin-d-roosevelt-1934.txt 858 2422 72
franklin-d-roosevelt-1935.txt 1145 3857 139
franklin-d-roosevelt-1936.txt 1215 4251 165
franklin-d-roosevelt-1937.txt 987 2977 104
franklin-d-roosevelt-1938.txt 1369 5117 173
franklin-d-roosevelt-1939.txt 1225 4165 168
franklin-d-roosevelt-1940.txt 1050 3511 121
franklin-d-roosevelt-1941.txt 1100 3658 148
franklin-d-roosevelt-1942.txt 1116 3912 170
franklin-d-roosevelt-1943.txt 1388 5071 200
franklin-d-roosevelt-1944.txt 1234 4219 167
franklin-d-roosevelt-1945a.txt 1035 3441 136
franklin-d-roosevelt-1945b.txt 2084 8895 338
george-bush-1989.txt 1505 5474 290
george-bush-1990.txt 1206 4312 198
george-bush-1991.txt 1302 4481 226
george-bush-1992.txt 1497 5771 320
george-w-bush-2001.txt 1298 4927 276
george-w-bush-2002.txt 1333 4323 215
george-w-bush-2003.txt 1661 6028 299
george-w-bush-2004.txt 1579 5790 275
george-w-bush-2005.txt 1576 5628 239
george-w-bush-2006.txt 1642 5908 276
george-w-bush-2007.txt 1689 6161 285
george-w-bush-2008.txt 1694 6345 310
gerald-r-ford-1975.txt 1327 4621 216
gerald-r-ford-1976.txt 1487 5505 271
gerald-r-ford-1977.txt 1478 5246 213
harry-s-truman-1946.txt 3956 30890 1266
harry-s-truman-1947.txt 1652 6619 291
harry-s-truman-1948.txt 1379 5575 274
harry-s-truman-1949.txt 1122 3764 185
harry-s-truman-1950.txt 1336 5588 232
harry-s-truman-1951.txt 1070 4415 229
harry-s-truman-1952.txt 1381 5919 292
harry-s-truman-1953.txt 2190 10869 431
jimmy-carter-1978a.txt 1340 5051 248
jimmy-carter-1978b.txt 2728 13225 507
jimmy-carter-1979a.txt 1071 3639 160
jimmy-carter-1979b.txt 3710 23426 861
jimmy-carter-1980a.txt 1070 3801 166
jimmy-carter-1980b.txt 4858 36401 1339
jimmy-carter-1981.txt 5188 36774 1332
john-f-kennedy-1961.txt 1714 5835 200
john-f-kennedy-1962.txt 2047 7419 269
john-f-kennedy-1963.txt 1677 6040 212
lyndon-b-johnson-1964.txt 1103 3603 139
lyndon-b-johnson-1965.txt 1344 4895 257
lyndon-b-johnson-1966.txt 1500 6174 265
lyndon-b-johnson-1967.txt 1842 8024 353
lyndon-b-johnson-1968.txt 1440 5524 208
lyndon-b-johnson-1969.txt 1208 4605 194
richard-m-nixon-1970.txt 1270 4934 192
richard-m-nixon-1971.txt 1149 4971 178
richard-m-nixon-1972a.txt 1164 4424 158
richard-m-nixon-1972b.txt 3286 18979 728
richard-m-nixon-1974a.txt 1267 5690 204
richard-m-nixon-1974b.txt 3815 24507 786
ronald-reagan-1981.txt 1382 4920 220
ronald-reagan-1982.txt 1608 5765 248
ronald-reagan-1983.txt 1681 6156 259
ronald-reagan-1984.txt 1612 5563 292
ronald-reagan-1985.txt 1478 4725 222
ronald-reagan-1986.txt 1260 3904 175
ronald-reagan-1987.txt 1343 4286 204
ronald-reagan-1988.txt 1506 5402 223
william-j-clinton-1993.txt 1564 7698 292
william-j-clinton-1994.txt 1767 8285 396
william-j-clinton-1995.txt 1939 10203 460
william-j-clinton-1996.txt 1584 7038 356
william-j-clinton-1997.txt 1719 7548 346
william-j-clinton-1998.txt 1964 8202 366
william-j-clinton-1999.txt 1932 8436 392
william-j-clinton-2000.txt 2113 10222 493
summary(sotu_corp,5)
Corpus consisting of 96 documents, showing 5 documents:
Text Types Tokens Sentences
barack-obama-2009.txt 1587 6743 286
barack-obama-2010.txt 1844 8151 419
barack-obama-2011.txt 1832 7741 395
barack-obama-2012.txt 1889 7836 415
barack-obama-2013.txt 1865 7580 361
Tokenize the corpus¶
The next step is tokenization, where we break down text into individual tokens: words, characters, and symbols. Here, we do remove numbers, punctuation, and symbols first.
Finally, we convert the tokens to lowercase and visualize the first tokens of the first document.
sotu_toks <-tokens(sotu_corp)# It removes separators (whitespaces)but we can remove numbers,punctuation, symbols
sotu_toks <- tokens(sotu_corp, remove_punct = TRUE)
print(sotu_toks)
Tokens consisting of 96 documents.
barack-obama-2009.txt :
[1] "Madam" "Speaker" "Mr" "Vice" "President" "Members"
[7] "of" "Congress" "the" "First" "Lady" "of"
[ ... and 6,028 more ]
barack-obama-2010.txt :
[1] "Madam" "Speaker" "Vice" "President"
[5] "Biden" "Members" "of" "Congress"
[9] "distinguished" "guests" "and" "fellow"
[ ... and 7,172 more ]
barack-obama-2011.txt :
[1] "Mr" "Speaker" "Mr" "Vice"
[5] "President" "Members" "of" "Congress"
[9] "distinguished" "guests" "and" "fellow"
[ ... and 6,823 more ]
barack-obama-2012.txt :
[1] "Mr" "Speaker" "Mr" "Vice"
[5] "President" "Members" "of" "Congress"
[9] "distinguished" "guests" "and" "fellow"
[ ... and 6,975 more ]
barack-obama-2013.txt :
[1] "Please" "everybody" "have" "a" "seat" "Mr"
[7] "Speaker" "Mr" "Vice" "President" "Members" "of"
[ ... and 6,736 more ]
barack-obama-2014.txt :
[1] "The" "President" "Mr" "Speaker" "Mr" "Vice"
[7] "President" "Members" "of" "Congress" "my" "fellow"
[ ... and 6,945 more ]
[ reached max_ndoc ... 90 more documents ]
sotu_toks <- tokens_tolower(sotu_toks)
sotu_toks [[1]][1:20]# first 20 tokens of document 1
[1] "madam" "speaker" "mr" "vice" "president"
[6] "members" "of" "congress" "the" "first"
[11] "lady" "of" "the" "united" "states"
[16] "she's" "around" "here" "somewhere" "i"
Keywords in context¶
To examine how a word is used in a wider context, we can search for keywords in context.
kwic() allows you to identify a keyword of interest, and see a number of words before and after it.
We can specify the number of context words to be displayed with the argument window.
The argument pattern also takes a wild card (*) and multiple keywords in a character vector.
kw_health <- kwic(sotu_toks, pattern="health*", window = 10)
head(kw_health)
Keyword-in-context with 6 matches.
[barack-obama-2009.txt, 448]
[barack-obama-2009.txt, 585]
[barack-obama-2009.txt, 683]
[barack-obama-2009.txt, 916]
[barack-obama-2009.txt, 1026]
[barack-obama-2009.txt, 2371]
import more oil today than ever before the cost of | health |
sake of a quick profit at the expense of a | healthy |
job creation restart lending and invest in areas like energy | health |
who can now keep their jobs and educate our kids | health |
will be able to receive extended unemployment benefits and continued | health |
of our dependence on oil and the high cost of | health |
care eats up more and more of our savings each
market people bought homes they knew they couldn't afford from
care and education that will grow our economy even as
care professionals can continue caring for our sick there are
care coverage to help them weather this storm now i
care the schools that aren't preparing our children and the
Using a vector, we can search for multiple patterns at once.
kw_health2 <- kwic(sotu_toks, pattern=c("health*","care"), window = 10)
head(kw_health2)
Keyword-in-context with 6 matches.
[barack-obama-2009.txt, 448]
[barack-obama-2009.txt, 449]
[barack-obama-2009.txt, 585]
[barack-obama-2009.txt, 683]
[barack-obama-2009.txt, 684]
[barack-obama-2009.txt, 916]
import more oil today than ever before the cost of | health |
more oil today than ever before the cost of health | care |
sake of a quick profit at the expense of a | healthy |
job creation restart lending and invest in areas like energy | health |
creation restart lending and invest in areas like energy health | care |
who can now keep their jobs and educate our kids | health |
care eats up more and more of our savings each
eats up more and more of our savings each year
market people bought homes they knew they couldn't afford from
care and education that will grow our economy even as
and education that will grow our economy even as we
care professionals can continue caring for our sick there are
We can also search for multi-word expressions.
kw_healthcare<- kwic(sotu_toks, pattern=phrase("health care"))
Select tokens¶
We also remove stopwords, which are words that are not particularly
useful for understanding the meaning of the text, like “an”, “have”, and
“about”. The command for this is tokens_select().
sotu_toks_nostop <- tokens_select(sotu_toks,
pattern = stopwords("english"),
selection="remove")
stopwords("english")
[1] "i" "me" "my" "myself" "we"
[6] "our" "ours" "ourselves" "you" "your"
[11] "yours" "yourself" "yourselves" "he" "him"
[16] "his" "himself" "she" "her" "hers"
[21] "herself" "it" "its" "itself" "they"
[26] "them" "their" "theirs" "themselves" "what"
[31] "which" "who" "whom" "this" "that"
[36] "these" "those" "am" "is" "are"
[41] "was" "were" "be" "been" "being"
[46] "have" "has" "had" "having" "do"
[51] "does" "did" "doing" "would" "should"
[56] "could" "ought" "i'm" "you're" "he's"
[61] "she's" "it's" "we're" "they're" "i've"
[66] "you've" "we've" "they've" "i'd" "you'd"
[71] "he'd" "she'd" "we'd" "they'd" "i'll"
[76] "you'll" "he'll" "she'll" "we'll" "they'll"
[81] "isn't" "aren't" "wasn't" "weren't" "hasn't"
[86] "haven't" "hadn't" "doesn't" "don't" "didn't"
[91] "won't" "wouldn't" "shan't" "shouldn't" "can't"
[96] "cannot" "couldn't" "mustn't" "let's" "that's"
[101] "who's" "what's" "here's" "there's" "when's"
[106] "where's" "why's" "how's" "a" "an"
[111] "the" "and" "but" "if" "or"
[116] "because" "as" "until" "while" "of"
[121] "at" "by" "for" "with" "about"
[126] "against" "between" "into" "through" "during"
[131] "before" "after" "above" "below" "to"
[136] "from" "up" "down" "in" "out"
[141] "on" "off" "over" "under" "again"
[146] "further" "then" "once" "here" "there"
[151] "when" "where" "why" "how" "all"
[156] "any" "both" "each" "few" "more"
[161] "most" "other" "some" "such" "no"
[166] "nor" "not" "only" "own" "same"
[171] "so" "than" "too" "very" "will"
sotu_toks_nostop
Tokens consisting of 96 documents.
barack-obama-2009.txt :
[1] "madam" "speaker" "mr" "vice" "president" "members" "congress"
[8] "first" "lady" "united" "states" "around"
[ ... and 3,000 more ]
barack-obama-2010.txt :
[1] "madam" "speaker" "vice" "president" "biden"
[6] "members" "congress" "distinguished" "guests" "fellow"
[11] "americans" "constitution"
[ ... and 3,698 more ]
barack-obama-2011.txt :
[1] "mr" "speaker" "mr" "vice" "president"
[6] "members" "congress" "distinguished" "guests" "fellow"
[11] "americans" "tonight"
[ ... and 3,512 more ]
barack-obama-2012.txt :
[1] "mr" "speaker" "mr" "vice" "president"
[6] "members" "congress" "distinguished" "guests" "fellow"
[11] "americans" "last"
[ ... and 3,690 more ]
barack-obama-2013.txt :
[1] "please" "everybody" "seat" "mr" "speaker" "mr" "vice"
[8] "president" "members" "congress" "fellow" "americans"
[ ... and 3,653 more ]
barack-obama-2014.txt :
[1] "president" "mr" "speaker" "mr" "vice" "president" "members"
[8] "congress" "fellow" "americans" "today" "america"
[ ... and 3,767 more ]
[ reached max_ndoc ... 90 more documents ]
We can do the same with tokens_remove( ,pattern=stopwords("en")).
Generating n-grams¶
An n-gram is a contiguous sequence of n items in a text.
tokens_ngrams() generates a set of n-grams (tokens in sequence) from a tokenized text object.
It gives all possible combinations of tokens.
toks_ngram <- tokens_ngrams(sotu_toks_nostop, n = 2:4)
head(toks_ngram[[1]], 30)
tail(toks_ngram[[1]], 30)
[1] "madam_speaker" "speaker_mr" "mr_vice"
[4] "vice_president" "president_members" "members_congress"
[7] "congress_first" "first_lady" "lady_united"
[10] "united_states" "states_around" "around_somewhere"
[13] "somewhere_come" "come_tonight" "tonight_address"
[16] "address_distinguished" "distinguished_men" "men_women"
[19] "women_great" "great_chamber" "chamber_speak"
[22] "speak_frankly" "frankly_directly" "directly_men"
[25] "men_women" "women_sent" "sent_us"
[28] "us_know" "know_many" "many_americans"
[1] "fear_challenges_time_summon" "challenges_time_summon_enduring"
[3] "time_summon_enduring_spirit" "summon_enduring_spirit_america"
[5] "enduring_spirit_america_quit" "spirit_america_quit_someday"
[7] "america_quit_someday_years" "quit_someday_years_now"
[9] "someday_years_now_children" "years_now_children_can"
[11] "now_children_can_tell" "children_can_tell_children"
[13] "can_tell_children_time" "tell_children_time_performed"
[15] "children_time_performed_words" "time_performed_words_carved"
[17] "performed_words_carved_chamber" "words_carved_chamber_something"
[19] "carved_chamber_something_worthy" "chamber_something_worthy_remembered"
[21] "something_worthy_remembered_thank" "worthy_remembered_thank_god"
[23] "remembered_thank_god_bless" "thank_god_bless_may"
[25] "god_bless_may_god" "bless_may_god_bless"
[27] "may_god_bless_united" "god_bless_united_states"
[29] "bless_united_states_america" "united_states_america_thank"
tokens_compound() generates n-grams more selectively. For example, you can make bi-grams using phrase() and a wild card (*)
toks_neg_bigram <- tokens_compound(sotu_toks_nostop, pattern = phrase("united *"))
toks_neg_bigram_select <- tokens_select(toks_neg_bigram, pattern = phrase("united_*"))
Collocations¶
A collocation is a sequence of words or terms that co-occur more often than would be expected by chance. Collocations can be more informative or meaningful than ngrams as they allow us to evaluate the strength and significance of the association between sequences of words.
sotu_collocations <- textstat_collocations(sotu_toks_nostop, method = "lambda", size = 2, min_count = 2,smoothing = 0.5)
head(sotu_collocations)
collocation count count_nested length lambda z
1 united states 709 0 2 7.885126 87.41215
2 last year 388 0 2 4.996601 70.81536
3 health care 235 0 2 6.353499 63.41266
4 american people 328 0 2 4.183064 61.56281
5 social security 231 0 2 6.452656 60.44997
6 federal government 277 0 2 4.307875 58.60510
Document feature matrix¶
We are going to create a document feature matrix (dfm) from a tokens object. We will then turn the dfm into a tidy data frame. A tidy data frame means one variable per column, one observation per row, one value per cell.
sotu_dfm <- dfm(sotu_toks)
sotu_dfm
dim(sotu_dfm)
Document-feature matrix of: 96 documents, 20,805 features (92.39% sparse) and 0 docvars.
features
docs madam speaker mr vice president members of congress the first
barack-obama-2009.txt 1 1 1 2 5 1 161 10 269 8
barack-obama-2010.txt 1 1 0 2 6 2 166 10 336 5
barack-obama-2011.txt 0 3 2 1 2 2 195 10 354 11
barack-obama-2012.txt 0 2 2 2 5 3 170 15 294 8
barack-obama-2013.txt 0 1 2 1 2 1 172 17 302 6
barack-obama-2014.txt 0 2 2 2 7 3 154 20 284 14
[ reached max_ndoc ... 90 more documents, reached max_nfeat ... 20,795 more features ]
[1] 96 20805
ndoc(sotu_dfm)
nfeat(sotu_dfm)
topfeatures(sotu_dfm, 10)
[1] 96
[1] 20805
the of and to in a we our that for
37864 23162 22842 21779 13935 10702 10156 9866 7908 7569
TF-IDF analysis¶
We can also do TF-IDF analysis (Term frequency-Inverse Document Frequency). The purpose of this type of analysis is to find a document’s most distinctive terms: How frequent a term is in a doc/how frequent it is across all docs. (High score=distinctive, Low score=not distinctive).
# Add a tf-idf on a dfm to determine a document's most distinctive words
sotu_tf_idf <- dfm_tfidf(sotu_dfm)
sotu_tf_idf
Document-feature matrix of: 96 documents, 20,805 features (92.39% sparse) and 0 docvars.
features
docs madam speaker mr vice president members of
barack-obama-2009.txt 1.20412 0.07918125 0.08464414 0.5841503 0.14014362 0.02802872 0
barack-obama-2010.txt 1.20412 0.07918125 0 0.5841503 0.16817234 0.05605745 0
barack-obama-2011.txt 0 0.23754374 0.16928828 0.2920752 0.05605745 0.05605745 0
barack-obama-2012.txt 0 0.15836249 0.16928828 0.5841503 0.14014362 0.08408617 0
barack-obama-2013.txt 0 0.07918125 0.16928828 0.2920752 0.05605745 0.02802872 0
barack-obama-2014.txt 0 0.15836249 0.16928828 0.5841503 0.19620107 0.08408617 0
features
docs congress the first
barack-obama-2009.txt 0 0 0.07314704
barack-obama-2010.txt 0 0 0.04571690
barack-obama-2011.txt 0 0 0.10057717
barack-obama-2012.txt 0 0 0.07314704
barack-obama-2013.txt 0 0 0.05486028
barack-obama-2014.txt 0 0 0.12800731
[ reached max_ndoc ... 90 more documents, reached max_nfeat ... 20,795 more features ]
#Simple frequency analysis
sotu_freq <- textstat_frequency(sotu_dfm)
head(sotu_freq, 20)
feature frequency rank docfreq group
1 the 37864 1 96 all
2 of 23162 2 96 all
3 and 22842 3 96 all
4 to 21779 4 96 all
5 in 13935 5 96 all
6 a 10702 6 96 all
7 we 10156 7 96 all
8 our 9866 8 96 all
9 that 7908 9 96 all
10 for 7569 10 96 all
11 is 5905 11 96 all
12 will 5334 12 96 all
13 i 5230 13 96 all
14 this 5104 14 96 all
15 have 4886 15 96 all
16 be 4083 16 96 all
17 are 3991 17 96 all
18 with 3722 18 96 all
19 on 3637 19 96 all
20 it 3528 20 96 all
Create a word cloud¶
We can use word clouds as a simple way to represent our corpus. This first version will likely time out, so make sure to stop the process to see the output.
textplot_wordcloud(sotu_dfm)

This word cloud is a bit overwhelming, so let’s pare it down a bit.
Here we add some specifications to limit the number of words included and to provide some aesthetic value. You shouldn’t need to halt this process.
textplot_wordcloud(sotu_dfm,
rotation = 0.25, #proportion of words with 90 degree rotation
color = rev(RColorBrewer::brewer.pal(10, "RdBu")))

Lexical diversity¶
Lexical diversity is a measure of how many times a word appears in a text and where it appears relative to the beginning of the document
sotu_lexdiv <- textstat_lexdiv(sotu_dfm)
head(sotu_lexdiv)
document TTR
1 barack-obama-2009.txt 0.2487967
2 barack-obama-2010.txt 0.2373709
3 barack-obama-2011.txt 0.2491568
4 barack-obama-2012.txt 0.2465636
5 barack-obama-2013.txt 0.2554831
6 barack-obama-2014.txt 0.2607883
Working with a subset¶
We can also work with a subset of the texts in the corpus. Here we do some additional pre-processing, before we create a subset containing only President Obama’s speeches.
sotu2 <- readtext("texts",
docvarsfrom = "filenames")
sotu2 <- sotu2 %>%
mutate(year= str_sub(.$docvar1, -5)) %>% # create year column
mutate(name= str_sub(.$docvar1, 1, -6)) # create name column
sotu2$year <- sotu2$year %>%
str_replace_all("[-ab]", "") # remove unwanted characters from the year column
sotu2$year <- as.integer(sotu2$year)
sotu2$name <- sotu2$name %>%
str_replace_all("-", " ") %>%
trimws() #trim leading and trailing whitespace from terms in name field\
sotu_corp2 <- corpus(sotu2)
obama_corpus <- corpus_subset(sotu_corp2, name=="barack obama")
From here, we can repeat the same steps we did above.
#Clean the tokens, create a dfm, and make it tidy
obama_toks <- tokens(obama_corpus, remove_numbers = TRUE, remove_punct = TRUE)
obama_toks <- tokens_remove(obama_toks, pattern = stopwords("english"))
obama_toks <- tokens_tolower(obama_toks)
obama_dfm <- dfm(obama_toks)
obama_dfm
Document-feature matrix of: 8 documents, 5,104 features (69.68% sparse) and 3 docvars.
features
docs madam speaker mr vice president members congress first lady
barack-obama-2009.txt 1 1 1 2 5 1 10 8 1
barack-obama-2010.txt 1 1 0 2 6 2 10 5 1
barack-obama-2011.txt 0 3 2 1 2 2 10 11 0
barack-obama-2012.txt 0 2 2 2 5 3 15 8 0
barack-obama-2013.txt 0 1 2 1 2 1 17 6 0
barack-obama-2014.txt 0 2 2 2 7 3 20 14 1
features
docs united
barack-obama-2009.txt 5
barack-obama-2010.txt 7
barack-obama-2011.txt 4
barack-obama-2012.txt 6
barack-obama-2013.txt 10
barack-obama-2014.txt 6
[ reached max_ndoc ... 2 more documents, reached max_nfeat ... 5,094 more features ]
We can look at keywords in context for this subset, as well.
#####Keywords in Context: What words immediately precede and follow terms of interest
kw_health <- kwic(obama_toks, "health*", window = 10)
head(kw_health)
Keyword-in-context with 6 matches.
[barack-obama-2009.txt, 206]
[barack-obama-2009.txt, 270]
[barack-obama-2009.txt, 321]
[barack-obama-2009.txt, 431]
[barack-obama-2009.txt, 486]
[barack-obama-2009.txt, 1146]
finding new sources energy yet import oil today ever cost
instead opportunity invest future regulations gutted sake quick profit expense
time jump-start job creation restart lending invest areas like energy
mass transit plan teachers can now keep jobs educate kids
americans lost jobs recession able receive extended unemployment benefits continued
another american century confront last price dependence oil high cost
| health |
| healthy |
| health |
| health |
| health |
| health |
care eats savings year yet keep delaying reform children compete
market people bought homes knew afford banks lenders pushed bad
care education grow economy even make hard choices bring deficit
care professionals can continue caring sick police officers still streets
care coverage help weather storm now know chamber watching home
care schools preparing children mountain debt stand inherit responsibility next
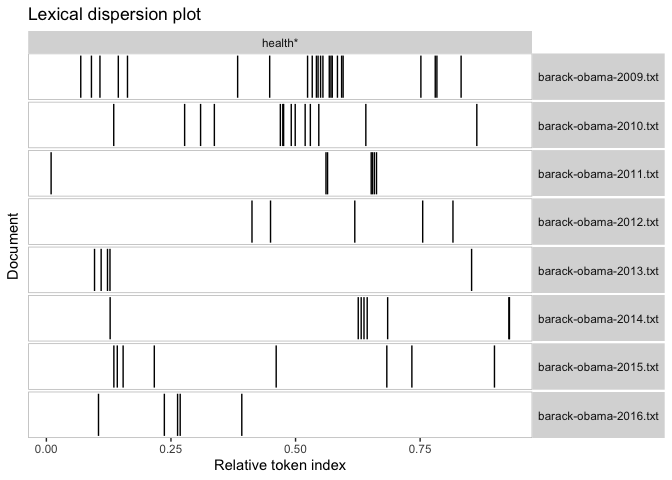
We can make a lexical dispersion plot to visualize where our keyword is appearing across the documents.
textplot_xray(kw_health)